Data Lake
Data Lake 是什麼
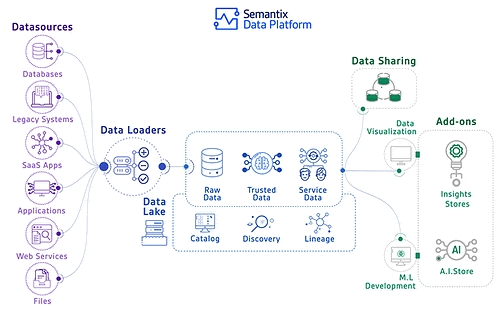
是什麼在 ByteByteGo 上看到一張有意思的 gif 圖片,是由 Semantix 畫的 Data Pipeline (處理資料流的系統) 示意圖。
其中Data Lake (資料池) 這個名詞吸引我的注意,常看到但根本不了解。
這篇文章分享我收集與瞭解的資料。
此篇文章主要參考 Technically Substack
1 Data Lake 的定義
Data Lake是無結構化存放數據的地方 (unstructured place to put data)。
主要是為了
長期儲存數據(long term storage )
不定時的查詢數據 (infrequent querying)
2 為什麼需要 Data Lake?
3 個原因
企業正在收集比以前還要多的數據,但不會都立刻使用到
用來長期存放數據,但不需特別定義 Schema (數據結構)
閱讀數據的人更容易理解 -> 這是跟Data Warehouses(資料倉儲) 相比,因 Data Warehouses需要事先定義 Schema
3 Data Lake 使用案例
先了解公司會儲存什麼樣的數據。
主要有 2種
Structured operational data (結構化的營運數據 ): 類似一張 Excel 資料表
Unstructured data (非結構化數據) : 想像一個 Key-Value paired (鍵值配對) 的資料,例如「姓名:朱騏, 職業: Technical Writer」
前者的範例有
Users(例如登入的使用者) & Organizations (註冊的公司)
產品銷售數據、訂單數量
SaaS app 數據 (例如 DAU, MAU)
產品的發票或付款數據 (例如金額、支付方式) 特色是有定義好的 Schema 儲存資料。
後者的範例有
文字數據 (例如 Twitter 使用者的 Tweet)
Server 或 Application 的效能數據 (例如System Log)
網站點擊數、瀏覽數
產品使用的瑣碎資料 (例如電商網站上的產品備註) 特色是不需符合關聯式資料庫的結構 (ex. SQL),因為數量太龐大、產生速度太快。
那這些數據可以如何使用呢?
Case 1: 營運場景 (例如日報、月報) 數據種類: 結構化的營運數據。例如
我們有多少的使用者
這個月我們賺多少錢
我們的顧客流失率是多少
Case 2: 專案場景(例如Machine Learning 專案、即時使用者觀察) 數據種類: 非結構化數據。例如Twitter 上的What's happening 動態牆,可即時顯示近幾個小時的熱門 Tweet。
4 Data Lake 和Data Warehouses 的差別
主要差異是
Data Warehouses: 適合存放結構化數據、經常性要使用的數據
Data Lake: 適合存放非結構化數據、為特殊目的使用
可以從下方 2 個點切入比較
Schema on write vs. Schema on read (寫入的數據結構 vs 讀取的數據結構)
Regular reporting vs. Special projects (經常性報告 vs 特殊專案)
Schema on write vs. Schema on read
Data Warehouses
必須先定義數據結構 (Data schema)
例如要追蹤使用者資訊,就必須先定義「哪些使用者的資料要寫到Data Warehouses 的欄位中」。
知名產品例如有Snowflake, BigQuery
Data Lake
不需先定義數據結構,可以將任意結構的數據丟進 Data Lake
當需要讀取時,再定義「讀取」的數據結構
多數的 Data Lake 都會使用 Object(物件) 格式進行儲存,把資料當成 1 個 Object 儲存
Regular reporting vs. Special projects
那如何決定要使用Data Lake 或 Data Warehouses呢? 看使用情境。
例如
考量速度: 想像在整理日報時,今天寫的 query 和昨天寫的 query 會有 90 % 相似,因此使用結構化數據會比較好。
考量成本: 如果是要為了特定專案 (例如產品推薦系統),事前定義詳細結構反而會太花時間,因此可使用非結構化數據。
難道一定要 2 選 1 嗎 ?
多數公司會選擇兩者併用,重點是「如何有效率地同時使用這兩個工具」。在 SaaS 產業中,許多新創公司會先從 Data Warehouses 開始,接著再投資 Data Lake 來收集非結構化的資料。
5 Data Lake 實際產品有哪些
多數是「雲服務提供商 (Cloud service provider)」的原生物件存儲產品 (native object storage products)。例如 AWS: S3 (Simple Storage Service) 服務中,有方便的 Lake Formation 可以快速建立 Data Lake。
另一個有名的是 Hadoop Filesystem(HDFS),它是一個「跨伺服器、可設定分散式檔案系統」的框架,可用來儲存非結構性的數據。
Last updated